
Navigating Enterprise AI
Strategic debates, dilemmas and decisions!

Introduction
In 2023, enterprises spent a mere $2.5 billion on generative AI, accounting for less than 1% of their total cloud expenditure, according to the Menlo Ventures 2023 Enterprise AI Survey. Despite AI being a top priority for nearly half of global CEOs—47%, as noted in EY’s CEO 2024 Outlook survey — only 13% of executives feel prepared to harness AI's transformative power, as highlighted by a survey from Weber Shandwick.
The promise of enterprise AI is staggering. With 70-80% of enterprise data being unstructured—residing in PDFs, images, audio/video files, Slack messages, and more—this untapped resource has been notoriously difficult to leverage at scale. Generative AI, however, is poised to change this landscape by not only unlocking a treasure trove of information but also refining, shaping, and enhancing it in unprecedented ways.
However, the road to harnessing generative AI is fraught with complex decisions that enterprises must navigate before making significant, and potentially irreversible investments. These decisions matter and could redefine business outcomes and competitive advantages. Should enterprises leverage AI to augment human capabilities or pursue large automation efforts? Is it wiser to build custom AI solutions, or should they purchase off-the-shelf products? Should they opt for open-source or closed-source AI solutions, and should they invest in small specialized models or larger ones? Additionally, what are the ethical implications of deploying AI?
These questions represent pressing challenges that businesses must navigate. This article delves into these critical considerations, offering insights into the high-stakes decisions that lie at the heart of enterprise AI adoption.
While this discussion focuses on strategic considerations rather than implementation and operational factors, the latter are equally important. For now, we turn our attention to five pivotal areas:
A. Automation vs. Augmentation
B. Build vs. Buy
C. Closed-source vs. Open-source
D. Model Dimensions & Scope: Big vs. Small Models, Specialized Models vs. General-purpose models
E. Ethical Considerations: Inspiration vs. Infringement, among others
Automation vs. Augmentation
Is AI fully replacing human tasks, or is it enhancing human capabilities by assisting with tasks? This is a pivotal question that can steer enterprise investments. For instance, from my experience in investment management, an industry that I believe is ripe for productivity gains with strategic adoption of AI/ML, I recognize that while some tasks can be automated, many benefit from having a human in the loop. For most fundamental active investors, the final decision to invest or not is often made by the portfolio manager and will likely always be human-led (famous last words!). Nevertheless, the due diligence process encompasses a diverse array of activities, at least some of which can be automated. These activities can range from gathering information from various documents to generating custom tables or charts to even drafting the first version of an investment memo. The initial draft may be subpar, as is often the case with a human analyst too, but it can significantly improve over time with feedback. I find it fascinating that, unlike typical software investments, AI systems could actually appreciate over time.
There might still be investment firms, particularly smaller ones with hands-on portfolio managers, who find the idea of an AI analyst appealing. These AI analysts offer the advantages of being indefatigable, always available, and unemotional, all at a fraction of the cost. The decision framework guiding how to use AI will vary by firm and will depend upon task complexity, accuracy requirements, data availability and quality, investment appetite, business goals, and regulation, among others. Enterprises will want to investigate these factors before making large sweeping investments in AI.
This decision matters because each approach can lead to a different economic place, influencing value creation and competitive advantage – now or in the future. When organizations focus on augmentation, they design technology to work alongside human employees. This collaboration can limit productivity and performance gains to what augmented humans can achieve, missing out on the full benefits of automation, such as greater standardization, security, speed, and precision.
However, while automation might offer more economic value in the long run, it is harder to achieve for tasks with complex dependencies. Consider the London Stock Exchange's Taurus project, launched in 1983 and abandoned in 1993 after losing around £75 million. The project aimed to automate the paper-based stock trading system but faced strong opposition from registrars, whose roles would be diminished, and underestimated the complexity of changing business processes. A revised design that included registrars increased project complexity. Integrating human registrars' systems with the automated exchange proved challenging, and the program failed, highlighting how the complexity of human roles makes full automation impractical. On the topic of what the redesign entailed, this article highlights:
“Reports indicate that following the requirements meant as much as 70% of the original system would need to be rewritten. Such significant modification essentially negated the value of purchasing the system and resulted in major challenges developing and testing the software.”
Full automation also raises crucial questions of accountability. It's easier to hold humans responsible for mistakes or poor performance than to assign blame to an AI agent. This complexity is further compounded when AI decisions impact significant financial or operational outcomes. A feedback session with an AI analyst responsible for millions in losses will not be nearly as satisfying for a portfolio manager as one with a human analyst.
Also, AI cannot be a panacea for poor enterprise processes. During my time at BCG working on digital transformation projects, I understood how precisely designed RPA (Robotic Process Automation) bots can function predictably on simple, structured workflows to drive desired operational outcomes. But modern AI, specifically Generative AI is much less deterministic. Organizations will want to understand well their existing systems, structures, and processes before implementing and scaling AI solutions that could potentially amplify their existing gaps and inefficiencies.
Build or Buy
After deciding on the type of AI system that aligns with their strategic goals, enterprises face the crucial question: Should they build it in-house or buy it from an external vendor? They might also choose to build with external help, a path I believe many large enterprises will likely take.
This build versus buy debate has gained new urgency in the AI world due to the unprecedented pace of change. In today's market, time to market can mean the difference between success and failure. The choice between developing proprietary AI systems or leveraging existing solutions is not straightforward. Building in-house offers the allure of customization and can help create a data-centered competitive advantage but also demands substantial resources, expertise, and time—luxuries many organizations can't afford. Conversely, off-the-shelf AI solutions promise rapid deployment and access to cutting-edge technologies but raise concerns about vendor lock-in and data security. The advent of powerful models like GPT-4 has further complicated this calculus, demonstrating that certain AI capabilities are out of reach for all but the largest tech giants.
In 2023, there was discussion around building custom models like Bloomberg GPT, but 2024 has seen more and more enterprises elect to finetune models or utilize RAG rather than build their own, as indicated by an A16Z survey.
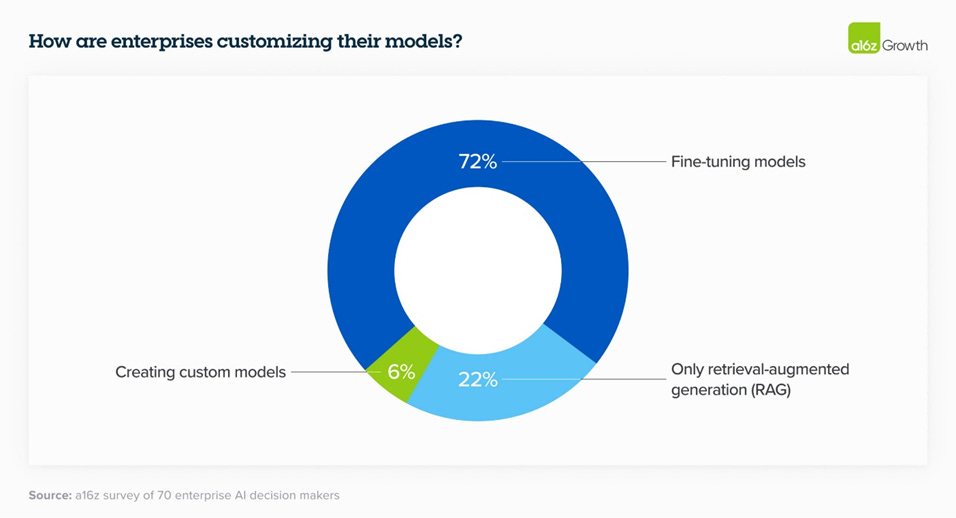
The build versus buy decision in AI extends beyond model development to critical areas such as observability, safety, and evaluation. Fiddler AI, in a recent blog post, argues that while 'good enough' homegrown observability tools might offer initial flexibility, they often prove unsustainable as AI deployments scale. Investing in specialized platforms designed for monitoring, explaining, and managing models at scale can be more beneficial in the long run. These solutions typically come with comprehensive features out-of-the-box, including support for diverse model tasks, flexible metric definitions, cross-framework compatibility, and scalability to meet growing demands.
Ultimately, organizations must conduct their own analyses and develop tailored strategies. The following six questions from an EY report provide a valuable framework for this evaluation:
How do total costs (implementation and operational) compare between building our own system versus buying an existing one?
Does our organization have the data, capability, and time to build an AI system that is better than what we can buy?
How do risks compare between building versus buying when considering emerging regulations?
Does building or buying fit better with our current operating model (or lack thereof) for AI?
What are the data privacy challenges related to buying versus building?
What risks could our organization face if purchase of an AI system leads to a vendor lock-in?
Closed-source or open source
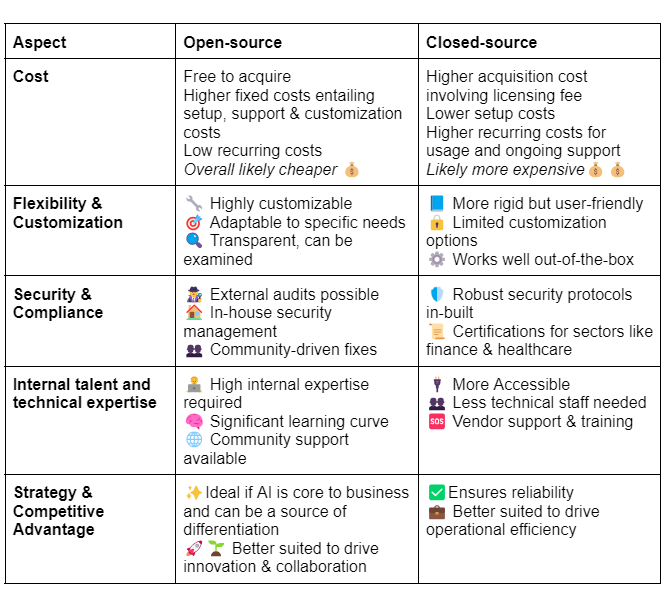
Enterprises opting to buy AI solutions externally must also decide between open-source or closed-source (proprietary) tools, models, and algorithms. Open-source solutions offer base models with open licenses, allowing for greater flexibility and control. This empowers users to adapt and integrate these tools into various systems with ease. In contrast, most closed-source solutions involve licensing access to proprietary models owned by the vendor. While these offer less freedom to modify or adapt, they are often considered to be of higher quality—though this gap is narrowing.
A recent A16Z survey highlights the growing interest in open-source. According to the survey, 46% of respondents prefer or strongly prefer open-source models heading into 2024. In interviews, nearly 60% of AI leaders expressed interest in increasing their use of open-source or switching when fine-tuned open-source models roughly matched the performance of closed-source ones. Interestingly, control and customization outweighed cost as the key drivers for this preference.
Here's a summary of the key factors enterprises should consider, based on my research and conversations with industry practitioners:
Model Dimensions & Scope
Are bigger models always better? Larger models like GPT-4 trained on trillions of parameters have demonstrated impressive capabilities across various tasks including question and answering, text completion, translation, summarization, and sentiment analyses, among others. However, these models also require significant computing resources!
For instance, Sam Altman had vaguely pegged the training cost of GPT-4 at “more than” $100m and Anthropic CEO Dario Amodei suggested in August last year that models costing over $1 billion would appear this year and that “by 2025 we may have a $10 billion model.”
On the other hand, smaller models, trained on a more focused dataset could excel in specific tasks or industries. Below is a visual representation by Data Science Dojo that I found helpful:

In this article, Salesforce claims that its open-source xGen model consistently exceeds the performance of larger models by leveraging better pre-training and data curation strategies. xGen, is trained on longer sequences of data, helping it summarize large volumes of text, write code, and more. They also observe that the models’ small size results in a more focused learning process: the models adapt faster to the nuances of particular datasets or applications. This is important for companies looking for specialized AI capabilities because they’re better at handling specific tasks.
However, theoretical scaling laws suggest that increasing model size should decrease loss or error rates, thereby improving performance. OpenAI researcher Jason Wei, in his blog on the intuitions behind LLMs, highlights that larger models benefit from emergent behaviors, where some tasks improve disproportionately. On scaling, he notes:
‘It is an open question why exactly scaling works, but here are two hand-wavy reasons. One is that small language models can’t memorize as much knowledge in their parameters, whereas large language models can memorize a huge amount of factual information about the world. A second guess is that while small language models are capacity-constrained, they might only learn first-order correlations in data. Large language models on the other hand, can learn complex heuristics in data.’
While specialized models tend to be smaller, this may not always be true. Bloomberg GPT, an LLM purpose-built for finance is trained on 50 billion parameters and would be considered large by most standards. However, this research paper indicates that GPT-4 outperforms Bloomberg GPT on most financial tasks.
The debate is very much ongoing. Smaller models like Mixtral 8x7B and Llama 2 – 70B have shown promising results in specific areas, such as reasoning and multiple-choice questions. In the same vein, this research paper by Google found that distilling knowledge from LLMs into smaller models resulted in models that performed similarly but with a fraction of the computational resources required.
For enterprises, factors like architecture, training data, and fine-tuning techniques can prove crucial in determining a model's performance and can guide the choice between large and small models. Additionally, they need to consider resource availability, budgets, specific needs, problem scope, scalability, and deployment complexity. These considerations help ensure that the selected model aligns with the enterprise’s goals and operational capabilities, optimizing both performance and resource efficiency.
Ethical considerations
There are many ethical considerations enterprises need to consider but the one I focus on in this section is the distinction between inspiration and infringement, a crucial area with potential legal ramifications.
“Every artist is a cannibal, every poet is a thief” - Bono
Is AI-generated content stolen? This question is only beginning to get addressed by the justice system as authors and artists sue AI providers over copyright infringement. Behind the magic of LLMs is massive training of data (text, images, videos) that the said AI, frankly speaking, has little to do with. Simply put, it belongs to others. But what if AI output is inspired or similar but not identical to existing works? In the world of art, getting inspired by the works of others is as common as chefs borrowing recipes from culinary traditions. This practice usually doesn't lead to legal action.
On this very matter, Hannah Kuker, Art & AI Intellectual Property Researcher at the University of Miami recently wrote a paper titled ‘ Inspiration Versus Infringement’. Laying out multiple ongoing suits like Getty Images vs Stability AI Inc, which alleges that infringement occurs at the training stage, Hannah argues that siding with claimants would set a dangerous precedent of data restriction, as AI companies would have to ask for permission to use copyrighted works in their database in a manner that contradicts existing rights to taking inspiration protected by copyright law. She instead suggests that AI art generators have the right to use copyrighted images for referential purposes unless the outputs meet the substantial similarity test.
What does this mean for enterprises? As it remains unclear at least for now, who owns the content that generative AI platforms create, businesses will be wise to understand these risks well to stay clear of legal troubles. Businesses may want to add protections to contracts, verify the proper licensure of the training data that feeds their AI, and potentially also seek broader indemnification for potential IP infringement caused by failures of the AI companies to properly license data. Enterprises using AI trained on proprietary data are naturally more protected in this department.
For example, Adobe’s Firefly model is trained on stock images for which Adobe holds the rights as well as on openly licensed content and public domain content. Additionally, Adobe recently unveiled the expansion of Firefly for enterprise users that will include ‘full indemnification’ for the content created through these features. Measures like these will help enterprise customers confidently embrace Generative AI.
Other important ethical considerations include:
Data privacy and security: With AI technologies collecting vast amounts of sensitive data, enterprises face ethical dilemmas in balancing AI-driven insights with protecting individual privacy. Data breaches can have legal and reputational consequences. Robust security measures and compliance with regulations are crucial for long-term confidence.
Bias and Fairness: AI algorithms can perpetuate existing biases in training data, leading to unfair outcomes in areas like hiring, lending, and law enforcement. Enterprises must actively work to identify and mitigate biases through diverse data collection, algorithmic transparency, and ethical guidelines in AI development.
Conclusion
The adoption of AI in enterprises presents a landscape filled with promise and complexity. As organizations navigate these uncharted waters, they must carefully consider the strategic decisions surrounding automation, procurement, model selection, and ethical considerations. By doing so, they can unlock the transformative potential of AI while mitigating risks and ensuring responsible use. The future of enterprise AI hinges not only on technological advancements but also on thoughtful, informed decision-making.
Loved reading this one. Very well summarised what most of our clients are thinking about.